[Avg. reading time: 9 minutes]
Data Integration
Data integration in the Big Data ecosystem differs significantly from traditional Relational Database Management Systems (RDBMS). While traditional systems rely on structured, predefined workflows, Big Data emphasizes scalability, flexibility, and performance.
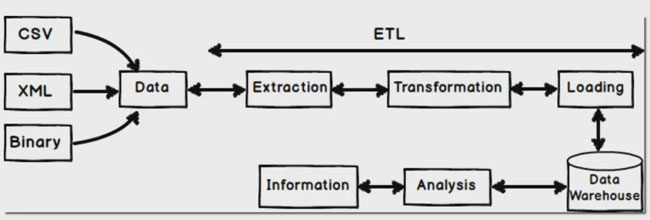
ETL: Extract Transform Load
ETL is a traditional data integration approach used primarily with RDBMS technologies such as MySQL, SQL Server, and Oracle.
Workflow
- Extract data from source systems.
- Transform it into the required format.
- Load it into the target system (e.g., a data warehouse).
ETL Tools
- SSIS / SSDT – SQL Server Integration Services / Data Tools
- Pentaho Kettle – Open-source ETL platform
- Talend – Data integration and transformation platform
- Benetl – Lightweight ETL for MySQL and PostgreSQL
ETL tools are well-suited for batch processing and structured environments but may struggle with scale and unstructured data.
src 1
src 2
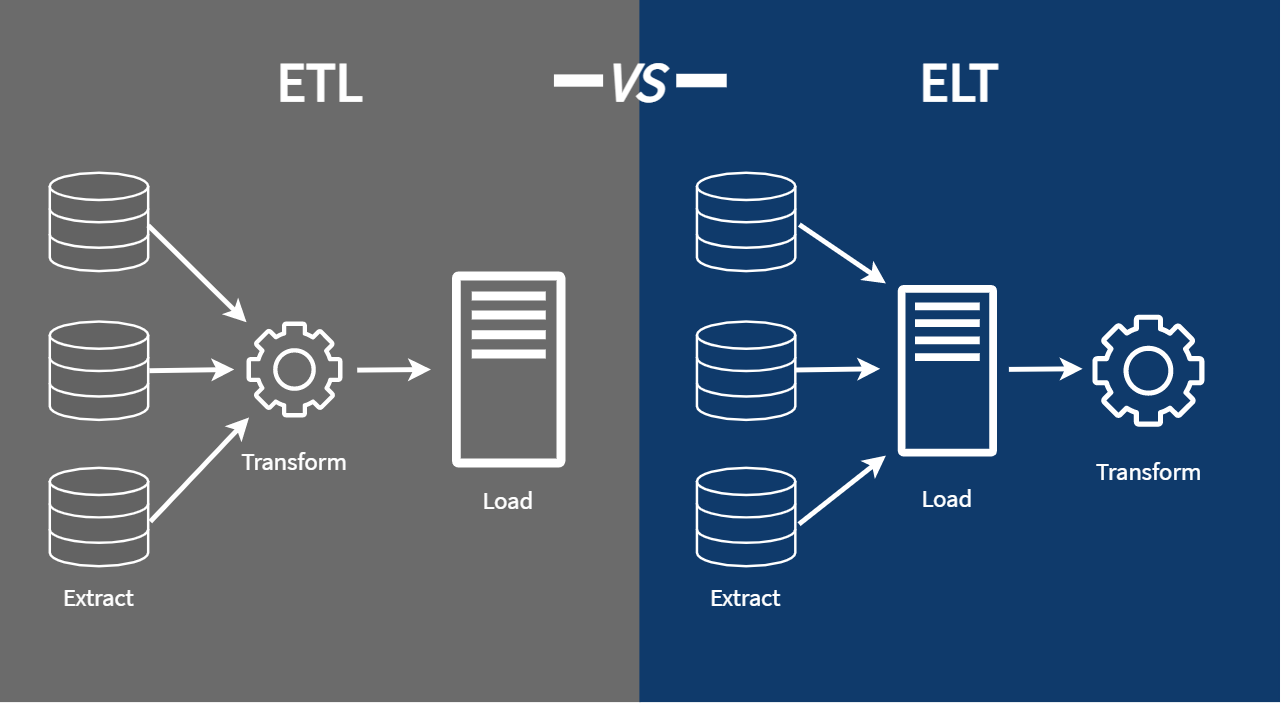
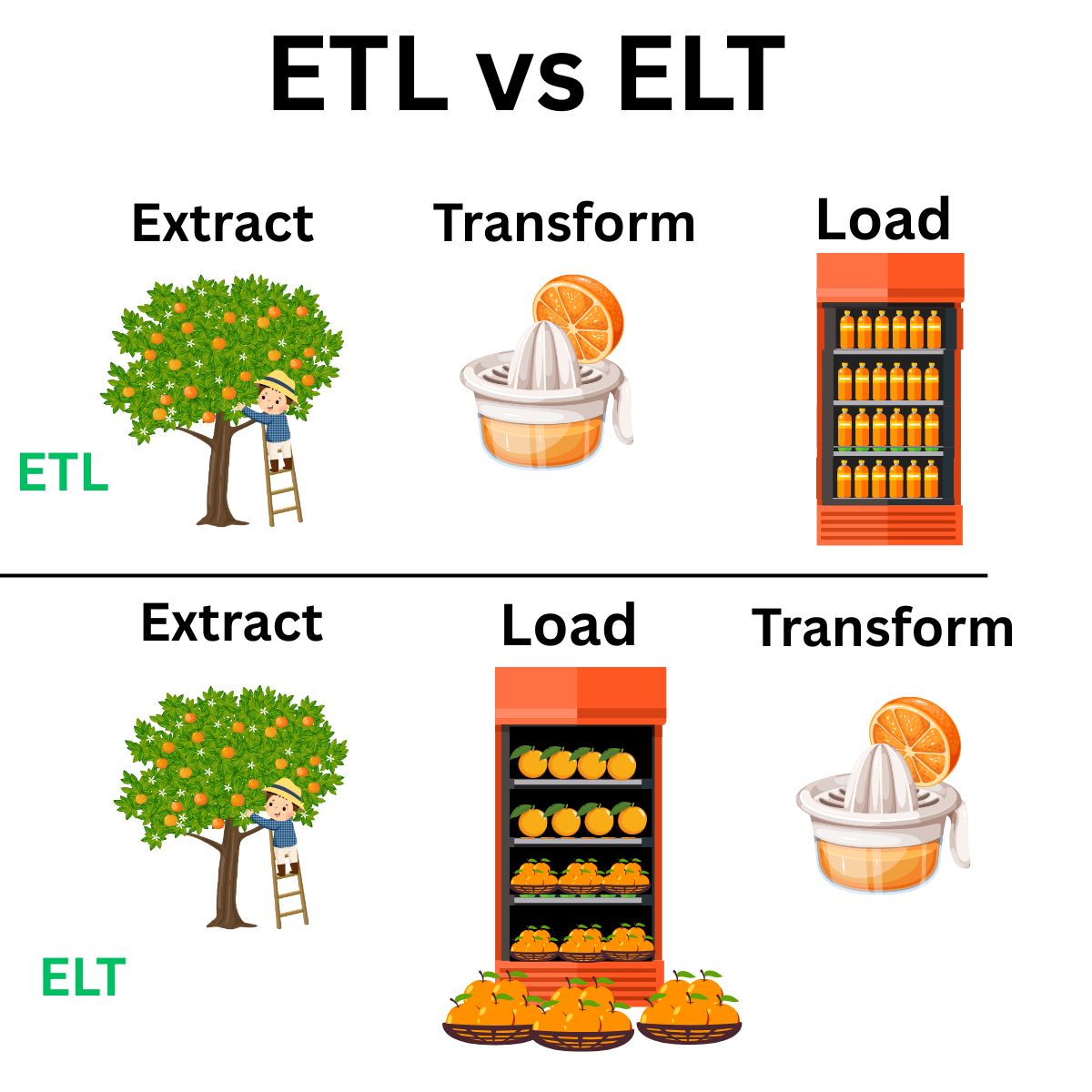
ELT: Extract Load Transform
ELT is the modern, Big Data-friendly approach. Instead of transforming data before loading, ELT prioritizes loading raw data first and transforming later.
Benefits
- Immediate ingestion of all types of data (structured or unstructured)
- Flexible transformation logic, applied post-load
- Faster load times and higher throughput
- Reduced operational overhead for loading processes
Challenges
- Security blind spots may arise from loading raw data upfront
- Compliance risks due to delayed transformation (HIPAA, GDPR, etc.)
- High storage costs if raw data is stored unfiltered in cloud/on-prem systems
ELT is ideal for data lakes, streaming, and cloud-native architectures.
Typical Big Data Flow
Raw Data → Cleansed Data → Data Processing → Data Warehousing → ML / BI / Analytics
- Raw Data: Initial unprocessed input (logs, JSON, CSV, APIs, sensors)
- Cleansed Data: Cleaned and standardized
- Processing: Performed through tools like Spark, DLT, or Flink
- Warehousing: Data is stored in structured formats (e.g., Delta, Parquet)
- Usage: Data is consumed by ML models, dashboards, or analysts
Each stage involves pipelines, validations, and metadata tracking.
#etl #elt #pipeline #rawdata #datalake
1: Leanmsbitutorial.com
2: https://towardsdatascience.com/how-i-redesigned-over-100-etl-into-elt-data-pipelines-c58d3a3cb3c