[Avg. reading time: 19 minutes]
Data Frames
DataFrames are the core abstraction for tabular data in modern data processing — used across analytics, ML, and ETL workflows.
They provide:
- Rows and columns like a database table or Excel sheet.
- Rich APIs to filter, aggregate, join, and transform data.
- Interoperability with CSV, Parquet, JSON, and Arrow.
Pandas
Pandas is a popular Python library for data manipulation and analysis. A DataFrame in Pandas is a two-dimensional, size-mutable, and heterogeneous tabular data structure with labeled axes (rows and columns).
Eager Evaluation: Pandas performs operations eagerly, meaning that each operation is executed immediately when called.
In-Memory Copy - Full DataFrame in RAM, single copy
Sequential Processing - Single threaded, one operation at at time.
Pros
- Easy to use and intuitive syntax.
- Rich functionality for data manipulation, including filtering, grouping, and merging.
- Large ecosystem and community support.
Cons
- Performance issues with very large datasets (limited by memory).
- Single-threaded operations, making it slower for big data tasks.
Example
import pandas as pd
# Load the CSV file using Pandas
df = pd.read_csv('data/sales_100.csv')
# Display the first few rows
print(df.head())
Polars
Polars is a fast, multi-threaded DataFrame library in Rust and Python, designed for performance and scalability. It is known for its efficient handling of larger-than-memory datasets.
Supports both eager and lazy evaluation.
Lazy Evaluation: Instead of loading the entire CSV file into memory right away, a Lazy DataFrame builds a blueprint or execution plan describing how the data should be read and processed. The actual data is loaded only when the computation is triggered (for example, when you call a collect or execute command).
Optimizations: Using scan_csv allows Polars to optimize the entire query pipeline before loading any data. This approach is beneficial for large datasets because it minimizes memory usage and improves execution efficiency.
- pl.read_csv() or pl.read_parquet() - eager evaluation
- pl.scan_csv() or pl.scan_parquet() - lazy evaluation
Parallel Execution: Multi-threaded compute.
Columnar efficiency: Uses Arrow columnar memory format under the hood.
Pros
- High performance due to multi-threading and memory-efficient execution.
- Lazy evaluation, optimizing the execution of queries.
- Handles larger datasets effectively.
Cons
- Smaller community and ecosystem compared to Pandas.
- Less mature with fewer third-party integrations.
Example
import polars as pl
# Load the CSV file using Polars
df = pl.scan_csv('data/sales_100.csv')
print(df.head())
# Display the first few rows
print(df.collect())
df1 = pl.read_csv('data/sales_100.csv')
print(df1.head())
Dask
Dask is a parallel computing library that scales Python libraries like Pandas for large, distributed datasets.
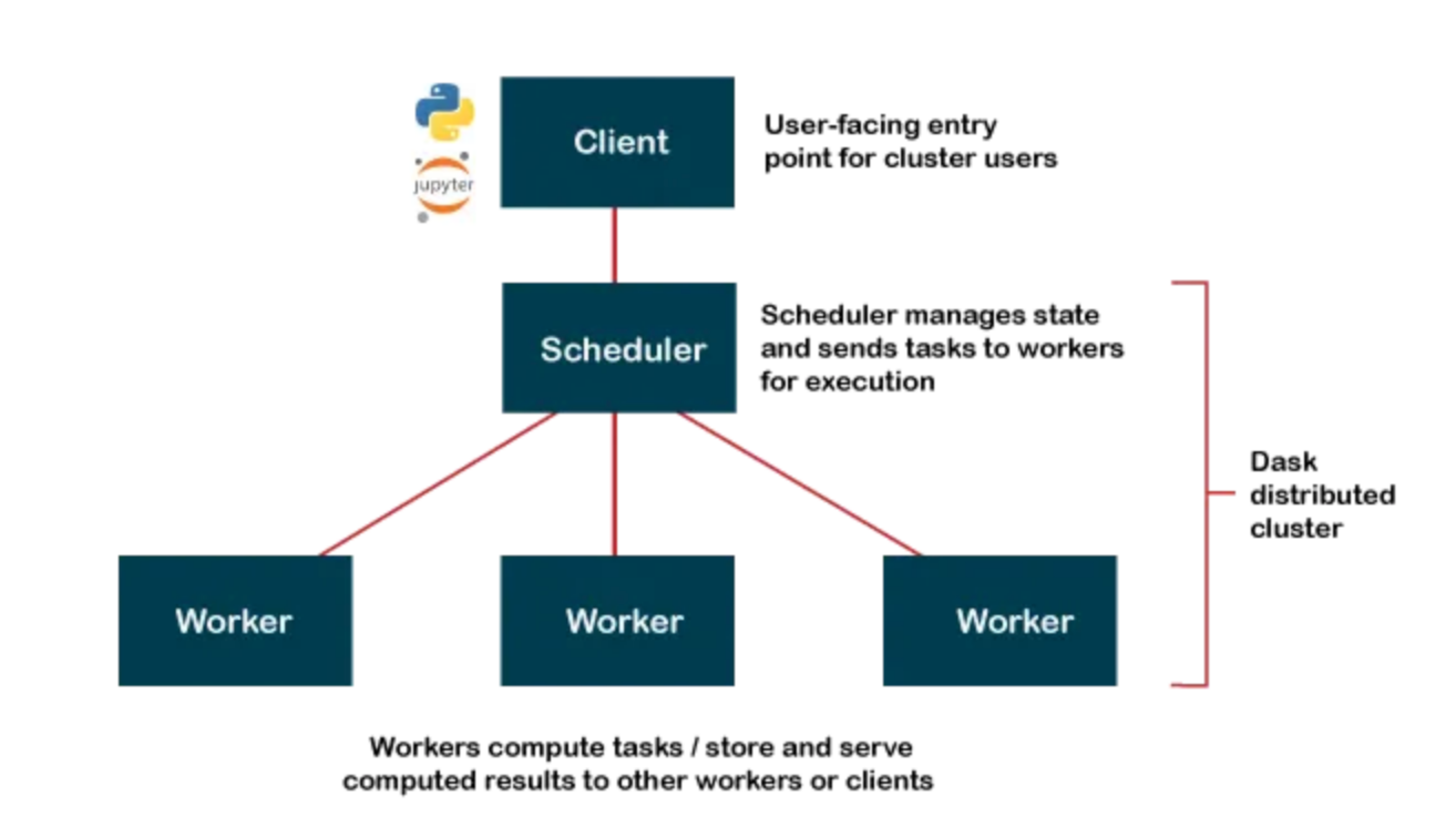
Client (Python Code)
│
▼
Scheduler (builds + manages task graph)
│
▼
Workers (execute tasks in parallel)
│
▼
Results gathered back to client
Open Source https://docs.dask.org/en/stable/install.html
Dask Cloud Coiled Cloud
Lazy Reading: Dask builds a task graph instead of executing immediately — computations run only when triggered (similar to Polars lazy execution).
Partitioning: A Dask DataFrame is split into many smaller Pandas DataFrames (partitions) that can be processed in parallel.
Task Graph: Dask represents your workflow as a directed acyclic graph (DAG) showing the sequence and dependencies of tasks.
Distributed Compute: Dask executes tasks across multiple cores or machines, enabling scalable, parallel data processing.
import dask.dataframe as dd
ddf = dd.read_csv(
"data/sales_*.csv",
dtype={"category": "string", "value": "float64"},
blocksize="64MB"
)
# 2) Lazy transform: per-partition groupby + sum, then global combine
agg = ddf.groupby("category")["value"].sum().sort_values(ascending=False)
# 3) Trigger execution and bring small result to driver
result = agg.compute()
print(result.head(10))
blocksize determines the parition. If omitted dask automatically uses 64MB
flowchart LR A1[CSV part 1] --> P1[parse p1] A2[CSV part 2] --> P2[parse p2] A3[CSV part 3] --> P3[parse p3] P1 --> G1[local groupby-sum p1] P2 --> G2[local groupby-sum p2] P3 --> G3[local groupby-sum p3] G1 --> C[combine-aggregate] G2 --> C G3 --> C C --> S[sort values] S --> R[collect to Pandas]
Pros
- Can handle datasets that don’t fit into memory by processing in parallel.
- Scales to multiple cores and clusters, making it suitable for big data tasks.
- Integrates well with Pandas and other Python libraries.
Cons
- Slightly more complex API compared to Pandas.
- Performance tuning can be more challenging.
Where to start?
- Start with Pandas for learning and small datasets.
- Switch to Polars when performance matters.
- Use Dask when data exceeds single-machine memory or needs cluster execution.
git clone https://github.com/gchandra10/python_dataframe_examples.git
Pandas vs Polars vs Dask
| Feature | Pandas | Polars | Dask |
|---|---|---|---|
| Language | Python | Rust with Python bindings | Python |
| Execution Model | Single-threaded | Multi-threaded | Multi-threaded, distributed |
| Data Handling | In-memory | In-memory, Arrow-based | In-memory, out-of-core |
| Scalability | Limited by memory | Limited to single machine | Scales across clusters |
| Performance | Good for small to medium data | High performance for single machine | Good for large datasets |
| API Familiarity | Widely known, mature | Similar to Pandas | Similar to Pandas |
| Ease of Use | Very easy, large ecosystem | Easy, but smaller ecosystem | Moderate, requires understanding of parallelism |
| Fault Tolerance | None | Limited | High, with task retries and rescheduling |
| Machine Learning | Integration with Python ML libs | Preprocessing only | Integration with Dask-ML and other libs |
| Lazy Evaluation | No | Yes | Yes, with task graphs |
| Best For | Data analysis, small datasets | Fast preprocessing on single machine | Large-scale data processing |
| Cluster Management | N/A | N/A | Supports Kubernetes, YARN, etc. |
| Use Cases | Data manipulation, analysis | Fast data manipulation | Large data, ETL, scaling Python code |