[Avg. reading time: 27 minutes]
Kafka
Introduction
Apache Kafka is a distributed streaming platform designed for high-throughput, fault-tolerant, real-time data pipelines. Its a publish-subscribe messaging system that excels at handling real-time data streams.
- Built at LinkedIn, open-sourced in 2011
- Designed as a distributed commit log
- Handles millions of events per second
- Extremely scalable and fault-tolerant
- Stores data durably for replay
Key Features
- High throughput: Can handle millions of messages per second
- Fault-tolerant: Data is replicated across servers
- Scalable: Can easily scale horizontally across multiple servers
- Persistent storage: Keeps messages for as long as you need
Apache Kafka is a publish/subscribe messaging system designed to solve this problem. It is often described as a “distributed commit log” or, more recently, as a “distributing streaming platform.”
A filesystem or database commit log is designed to provide a durable record of all transactions so that they can be replayed to build the state of a system consistently.
Basic Terms
Topic
Think of it like a TV Channel or Radio station where messages are published. A category or feed name to which messages are stored and published.
Key characteristics
- Multi-subscriber (multiple consumers can read from same topic)
- Durable (messages are persisted based on retention policy)
- Ordered (within each partition)
- Like a database table, but with infinite append-only logs
Messages
- The fundamental unit of data in Kafka
- Similar to a row in a database, but immutable (can’t be changed once written)
Structure of a message
- Value: The actual data payload (array of bytes)
- Key: Optional identifier (more on this below)
- Timestamp
- Optional metadata (headers)
Messages don’t have a specific format requirement - they’re just bytes.
Sample Message
+-------------------------------------------------------------+
| Kafka Record |
+-------------------------------------------------------------+
| Key (bytes) | Optional. Used for partitioning |
+-------------------------------------------------------------+
| Value (bytes) | Actual payload (JSON/Avro/Proto…) |
+-------------------------------------------------------------+
| Timestamp | CreateTime or LogAppendTime |
+-------------------------------------------------------------+
| Headers (optional) | Arbitrary metadata (byte key/value)|
+-------------------------------------------------------------+
| Topic | Logical stream name |
+-------------------------------------------------------------+
| Partition | Defines ordering and parallelism |
+-------------------------------------------------------------+
| Offset | Sequential id within the partition |
+-------------------------------------------------------------+
When the Producer sends
{
"key": "user_123",
"value": {
"userId": "user_123",
"action": "login",
"device": "iPhone",
"location": "New York"
},
"headers": {
"traceId": "abc-123-xyz",
"version": "1.0",
"source": "mobile-app"
}
}
consumer receives
{
"topic": "user_activities",
"partition": 2,
"offset": 15,
"timestamp": "2024-11-13T14:30:00.123Z",
"key": "user_123",
"value": {
"userId": "user_123",
"action": "login",
"device": "iPhone",
"location": "New York"
},
"headers": {
"traceId": "abc-123-xyz",
"version": "1.0",
"source": "mobile-app"
}
}
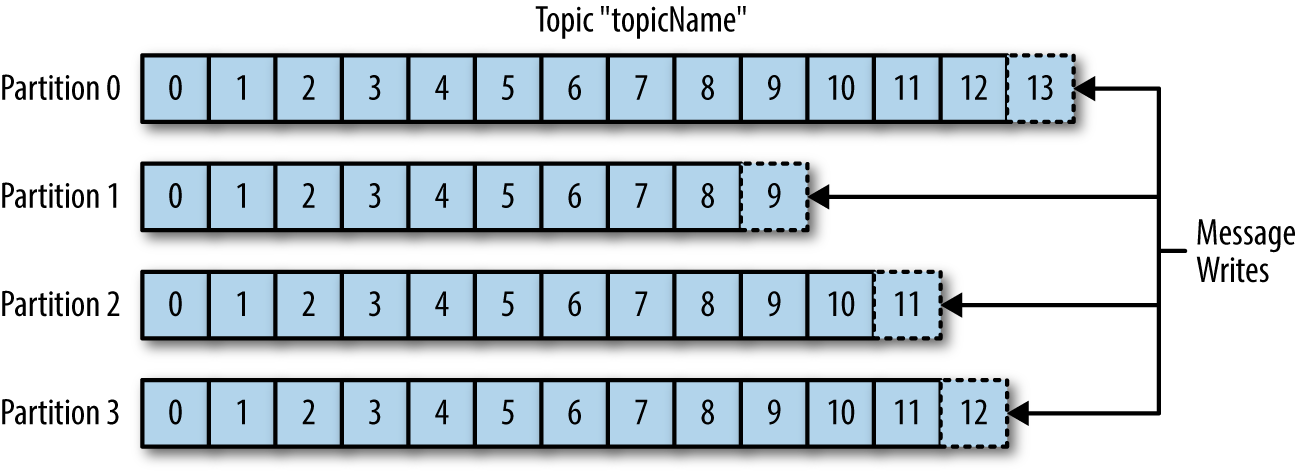
Partitions
- Topics are broken down into multiple partitions
- Messages are written in an append-only fashion
Important aspects
- Each partition is an ordered, immutable sequence of messages
- Messages get a sequential ID called an “offset” within their partition
- Time-ordering is guaranteed only within a single partition, not across the entire topic
- Provides redundancy and scalability
- Can be hosted on different servers
Keys
An optional identifier for messages serves two main purposes:**
Partition Determination:
- Messages with same key always go to same partition
- No key = round-robin distribution across partitions
- Uses formula: hash(key) % number_of_partitions
Data Organization:
- Groups related messages together
- Useful for message compaction
Real-world Example:
Topic: "user_posts"
Key: userId
Message: post content
Partitions: Multiple partitions for scalability
Result: All posts from the same user (same key) go to the same partition, maintaining order for that user's posts
Offset
A unique sequential identifier for messages within a partition, starts at 0 and increments by 1 for each message
Important characteristics:
- Immutable (never changes)
- Specific to a partition
- Used by consumers to track their position
- Example: In a partition with 5 messages → offsets are 0, 1, 2, 3, 4
Offset is a collaboration between Kafka and consumers:
- Kafka maintains offsets in a special internal topic called __consumer_offsets
This topic stores the latest committed offset for each partition per consumer group
Format in __consumer_offsets:
Key: (group.id, topic, partition)
Value: offset value
Two types of offsets for consumers:
- Current Position: The offset of the next message to be read
- Committed Offset: The last offset that has been saved to Kafka
Two types of Commits
- Auto Commit, default at a given interval in milli seconds.
- Manual Commit, done by consumer.
Batches
A collection of messages, all for the same topic and partition.
Benefits:
- More efficient network usage
- Better compression
- Faster I/O operations
Trade-off: Latency vs Throughput (larger batches = more latency but better throughput)
Producers
Producers create new messages. In general, a message will be produced on a specific topic.
Key behaviors:
- Can send to specific partitions or let Kafka handle distribution
Partition assignment happens through:
-
Round-robin (when no key is provided)
-
Hash of key (when message has a key)
-
Can specify acknowledgment requirements (acks)
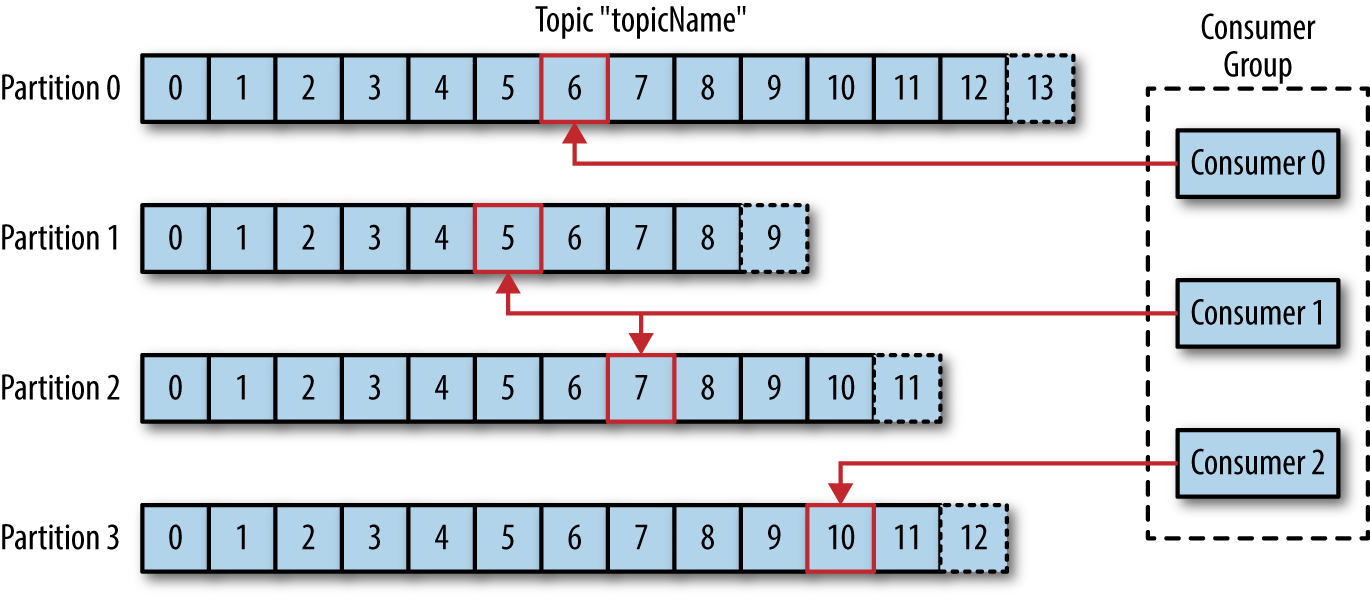
Consumers and Consumer Groups
Consumers read messages from topics
Consumer Groups:
- Multiple consumers working together
- Each partition is read by ONLY ONE consumer in a group
- Automatic rebalancing if consumers join/leave the group
src: Oreilly Kafka Book
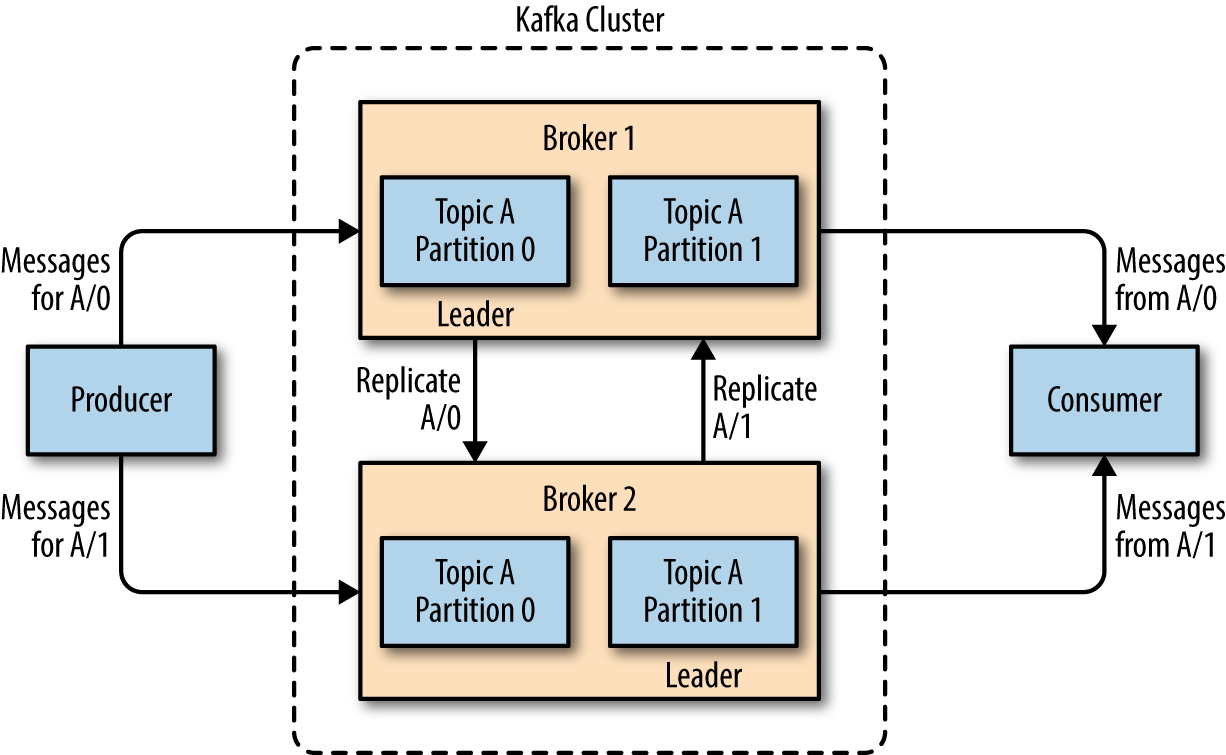
Brokers and Clusters
Broker:
Single Kafka server Responsibilities:
- Receive messages from producers
- Assign offsets
- Commit messages to storage
- Serve consumers
Cluster:
- Multiple brokers working together
- One broker acts as the Controller
- Handles replication and broker failure
- Provides scalability and fault tolerance
- A partition may be assigned to multiple brokers, which will result in Replication.
src: Oreilly Kafka Book
Message Delivery Semantics
Message Delivery Semantics are primarily controlled through Producer and Consumer configurations, not at the broker level.
At Least Once Delivery:
- Messages are never lost but might be redelivered.
- This is the default delivery method.
Scenario
- Consumer reads message
- Processes the message
- Crashes before committing offset
- After restart, reads same message again - retries > 0
Best for cases where duplicate processing is acceptable
from kafka import KafkaProducer
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
acks='all', # Strong durability (optional but recommended)
retries=5, # Enables retry → allows duplicates
enable_idempotence=False # Required for at-least-once (duplicates allowed)
)
producer.send('events', b'sample message')
producer.flush()
Consumer
from kafka import KafkaConsumer
consumer = KafkaConsumer(
'events',
bootstrap_servers=['localhost:9092'],
group_id='my_group',
enable_auto_commit=False, # Manual commit required for at-least-once
auto_offset_reset='earliest'
)
for msg in consumer:
# Process the message
print(msg.value)
# Commit only AFTER processing — ensures at-least-once
consumer.commit()
At Most Once Delivery:
- Messages might be lost but never redelivered
- Commits offset as soon as message is received
- Use when some data loss is acceptable but duplicates are not - retry = 0
from kafka import KafkaProducer
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
acks='all', # Strong durability (optional but recommended)
retries=0, # No Retry
enable_idempotence=False # Required for at-least-once (duplicates allowed)
)
producer.send('events', b'sample message')
producer.flush()
Consumer
enable_auto_commit=True auto_commit_interval_ms > 0
from kafka import KafkaConsumer
consumer = KafkaConsumer(
'events',
bootstrap_servers=['localhost:9092'],
group_id='my_group',
enable_auto_commit=True,
auto_offset_reset='earliest'
auto_commit_interval_ms=1000
)
for msg in consumer:
print(msg.value)
Exactly Once Delivery
- Messages are processed exactly once
- Achieved through transactional APIs
- Higher overhead but strongest guarantee - enable_idempotence=True
from kafka import KafkaProducer
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
acks='all', # Must wait for all replicas
enable_idempotence=True, # Core requirement for EOS
retries=5, # Required (Kafka enforces this)
transactional_id='txn-1' # Required for transactions
)
# Initialize the transaction
producer.init_transactions()
# Start transaction
producer.begin_transaction()
# Send messages inside the transaction
producer.send('events', b'event one')
producer.send('events', b'event two')
# Commit transaction atomically
producer.commit_transaction()
Summary
- At Most Once: Highest performance, lowest reliability
- At Least Once: Good performance, possible duplicates
- Exactly Once: Highest reliability, lower performance
Can Producer and Consumer have different semantics? Like producer with Exactly Once and Consumer with Atleast Once?
Yes its possible.
# Producer with Exactly Once
exactly_once_producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
acks='all',
enable_idempotence=True,
transactional_id='prod-1'
)
# Consumer with At Least Once
at_least_once_consumer = KafkaConsumer(
'your_topic',
bootstrap_servers=['localhost:9092'],
group_id='my_group',
enable_auto_commit=False, # Manual commit
auto_offset_reset='earliest'
# Note: No isolation_level setting needed
)
Transcation ID & Group ID
transactional_id
- A unique identifier for a producer instance
- Ensures only one active producer with that ID
- Required for exactly-once message delivery
- If a new producer starts with same transactional_id, old one is fenced off
group_id
- Identifies a group of consumers working together
- Multiple consumers can share same group_id
- Used for load balancing - each partition assigned to only one consumer in group
- Manages partition distribution among consumers
| Feature | transactional_id | group_id |
|---|---|---|
| Purpose | Exactly-once delivery | Consumer scaling |
| Uniqueness | Must be unique | Shared |
| Active instances | One at a time | Multiple allowed |
| State management | Transaction state | Offset management |
| Failure handling | Fencing mechanism | Rebalancing |
| Scope | Producer only | Consumer only |