[Avg. reading time: 11 minutes]
Terms to know
The Redis server is the heart of the Redis system, handling all data storage, processing, and management tasks.
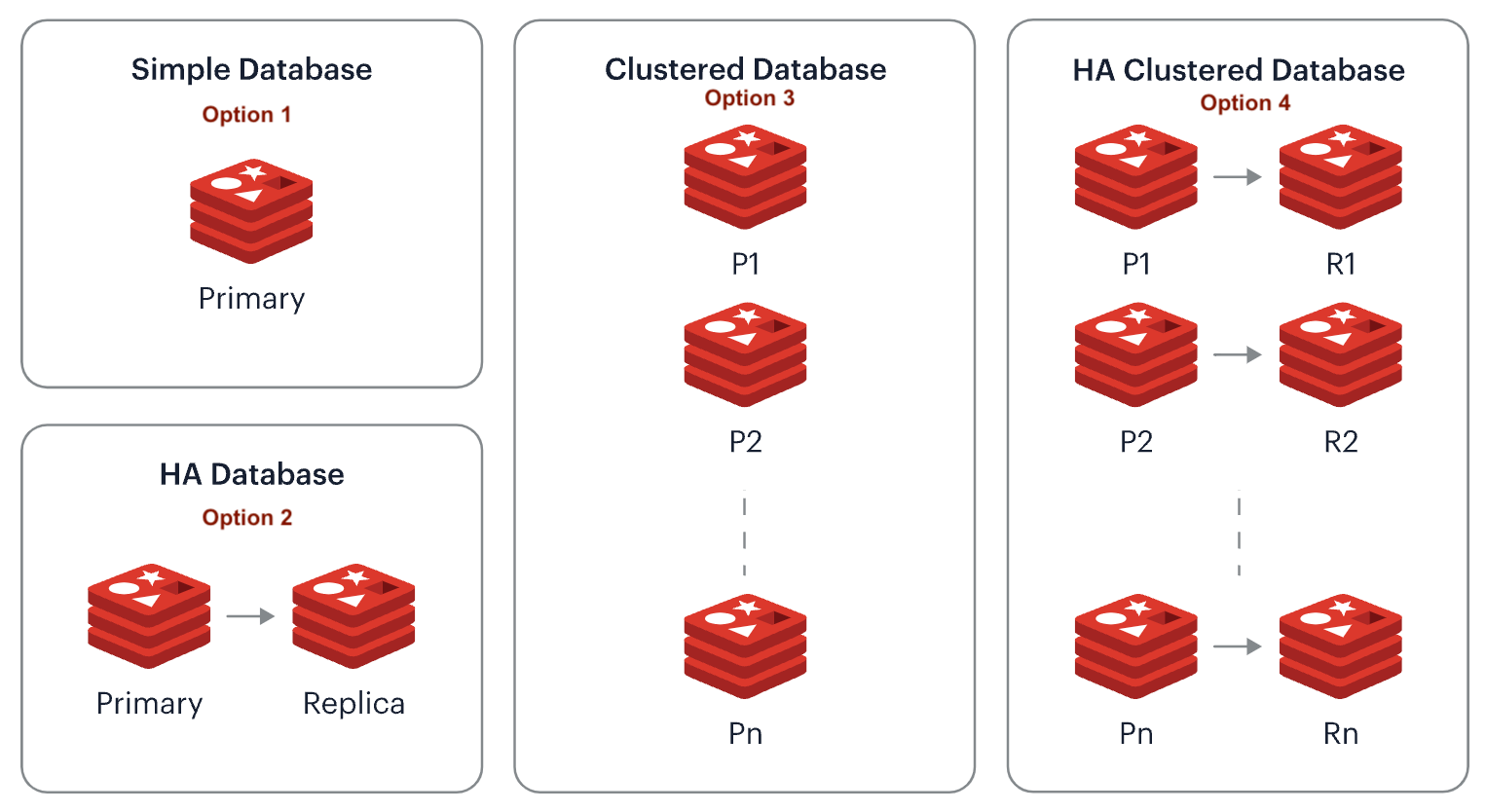
- A simple database, i.e., a single primary shard.
- A highly available (HA) database, i.e., a pair of primary and replica shards.
- A clustered database contains multiple primary shards, each managing a subset of the dataset.
- An HA clustered database, i.e., multiple pairs of primary/replica shards.
Shard: Splitting data across multiple Redis instances to distribute load and data volume. It's like breaking a big dataset into smaller, manageable pieces.

def get_shard(key, total_shards=3):
# Simple hash function to determine shard
hash_value = hash(key)
shard_number = hash_value % total_shards
print(f"shard:{shard_number}")
get_shard("user:1001")
get_shard("user:1002")
get_shard("user:1003")
get_shard("user:1004")
get_shard("user:1005")
get_shard("user:1006")
get_shard("user:1007")
Cluster: A group of Redis nodes that share data. Provides a way to run Redis where data is automatically sharded across nodes.
Replication is copying data from one Redis server to another for redundancy and scalability. The primary server's data is replicated to one or more secondary (replica) servers.
Transactions: Grouping commands to be executed as a single isolated operation, ensuring atomicity.
Atomicity - The most important reason to use transactions is that they guarantee all commands will be executed together without any other client's commands interrupting them.
Consistency in reads - Within a transaction, you get a consistent view of the data. Commands see the data as it was when the transaction started, not as it changes during the transaction.
Batch operations - Transactions reduce network overhead by sending multiple commands in a single request, which improves performance.
Optimistic locking with WATCH - When combined with the WATCH command, transactions provide a way to ensure data hasn't changed since you last read it.
No Rollbacks
Pipeline: Bundling multiple commands to reduce request/response latency. Commands are queued and executed at once.
Persistence: Saving data to disk for durability. Redis offers RDB (snapshotting) and AOF (logging every write operation).
RDB (Redis Database)
RDB periodically creates point-in-time snapshots of your dataset at specified intervals. It is generally faster for larger datasets because it doesn't write every disk change, reducing I/O overhead.
AOF (Append Only File)
Durability: Records every write operation received by the server. You can configure the fsync policy to balance between durability and performance.
Data Loss Risk: Less risk of data loss compared to RDB. It can be configured to append each operation to the AOF file as it happens or every second.
Recovery Speed: Slower restarts compared to RDB because Redis replays the entire AOF to rebuild the state.
Multi-Model Database
- Redis-Core - Key-Value Store
- Extend with Redis Modules
- Redis Search - Elastic Search
- RedisGraph - Graph Database
- RedisJSON - Document Database
- RedisTimeSeries - TimeSeries Database